Trust to Train and Train to Trust: Agent Training Programs for Safety-Critical Environments
Research Motivation
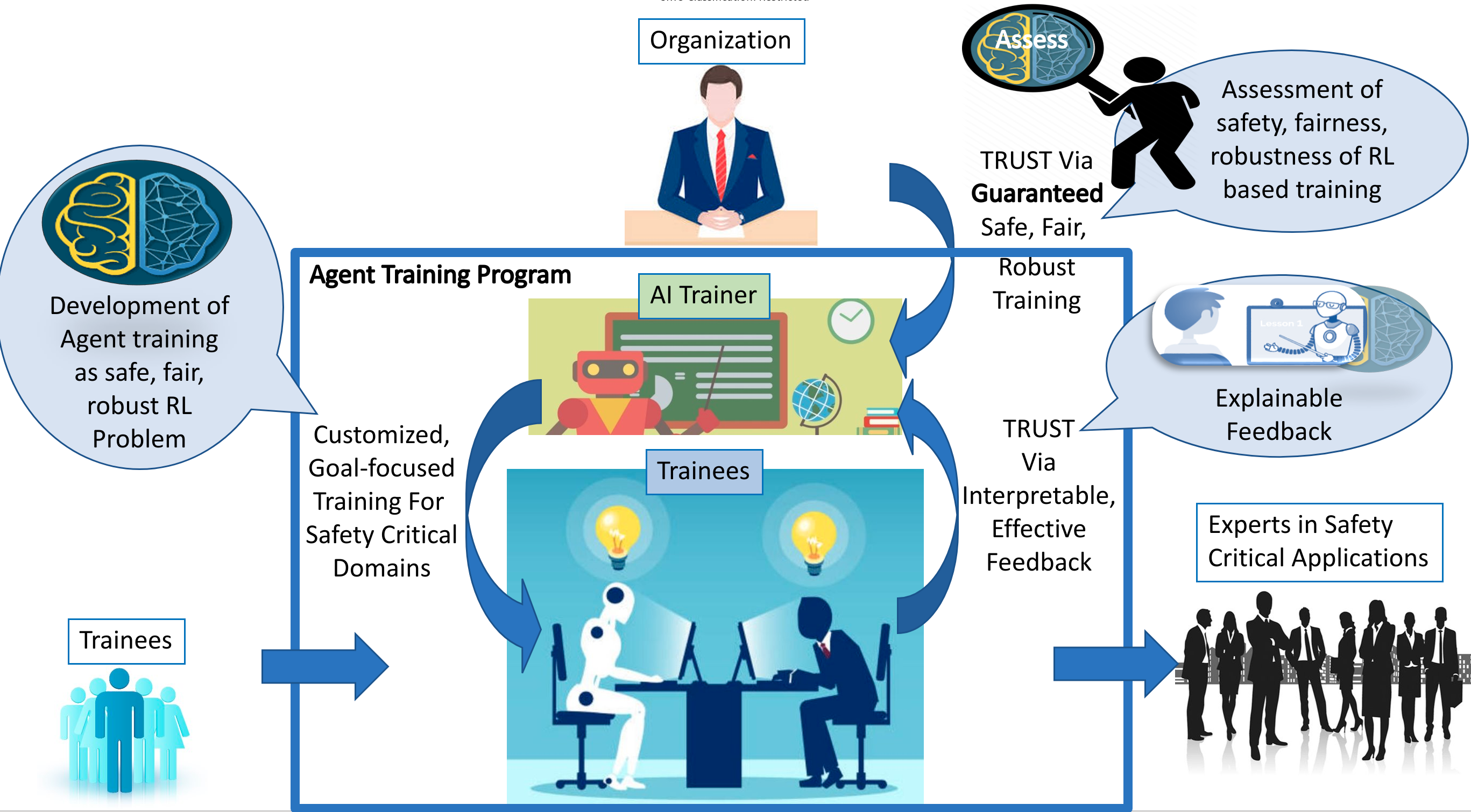 Artifical Intelligence systems have been able to achieve super-human performance in specific yet complex tasks across diverse problems. If such task specific AI agents can transfer knowledge in a trustworthy manner to humans that aim to add that specific skill, it will hugely benefit “skilled resource” starved environments. There are three fundamental research objectives and one integrated show-case objective in this project. The first objective is to develop agent training programs (ATPs) that train human trainees on all training outcomes, while being trustworthy. This entails developing learning and decision making frameworks for training that are safe, robust and fair (from the perspective of the organization employing the training), while being personalized (training that customizes to learning rate of trainee) and allowing trainees to ask counterfactual (what-if) questions for understanding the impact of alternative responses. To ensure effective generalization to trainees and situations not explicitly considered during development, the second objective is to assess the ATPs on their generalizability. Specifically, this would entail defining and computing trustworthiness scores (from organization’s perspective) of the training algorithms with respect to safety, fairness and robustness. The third objective is to develop feedback (explainable and effective) interfaces to provide in-situ and after training understandable feedback for trainees to improve their performance. Finally, we aim to integrate all three research objectives in show-case projects on training personnel in emergency response and maritime navigation. We will evaluate the trainer performance, w.r.t, safety, fairness, robustness of training; and trainee performance with respect to improvement of trainee capability.
Artifical Intelligence systems have been able to achieve super-human performance in specific yet complex tasks across diverse problems. If such task specific AI agents can transfer knowledge in a trustworthy manner to humans that aim to add that specific skill, it will hugely benefit “skilled resource” starved environments. There are three fundamental research objectives and one integrated show-case objective in this project. The first objective is to develop agent training programs (ATPs) that train human trainees on all training outcomes, while being trustworthy. This entails developing learning and decision making frameworks for training that are safe, robust and fair (from the perspective of the organization employing the training), while being personalized (training that customizes to learning rate of trainee) and allowing trainees to ask counterfactual (what-if) questions for understanding the impact of alternative responses. To ensure effective generalization to trainees and situations not explicitly considered during development, the second objective is to assess the ATPs on their generalizability. Specifically, this would entail defining and computing trustworthiness scores (from organization’s perspective) of the training algorithms with respect to safety, fairness and robustness. The third objective is to develop feedback (explainable and effective) interfaces to provide in-situ and after training understandable feedback for trainees to improve their performance. Finally, we aim to integrate all three research objectives in show-case projects on training personnel in emergency response and maritime navigation. We will evaluate the trainer performance, w.r.t, safety, fairness, robustness of training; and trainee performance with respect to improvement of trainee capability.
While the target is to develop fully trustworthy ATPs, the resulting guarantees on trustworthiness do not generalize due to two reasons: 1) It is computationally infeasible to fully explore the scenario and policy spaces. 2) It is infeasible to consider all possible prior knowledge for trainees. This is due to difficulty in enumerating all trainee behaviors, modelling humans accurately, enumerating all possible environment situations and developing exact methods. Hence, we consider designing trustworthiness scores for ATPs in this research. The goal is to determine whether the training programs satisfy safety, robustness and fairness with respect to the intended learning outcomes of training, irrespective of trainee abilities, modelling errors and environment complexity. As an output of this automated assessment process, we intend to define and compute a trustworthiness vector, which quantifies the trust on the ATPs in terms of safety, robustness and fairness of scenarios as well as training accuracy for different trainees. Such assessment can be used by the organization deploying ATPs to trust the training system as well as aid in official certification processes.
Techniques for trustworthiness assessment are often based on formal methods (FM), i.e., verification with mathematical guarantees, or automated testing (AT), i.e., systematic exploration of the system state space. Exploration of techniques for the trustworthiness assessment of Single and Multi-Agent RL has only recently begun with many open questions. How can we deal with the high dimensional environment state space of RL? How can we identify catastrophic experiences (state updates) for RL? How can we do so efficiently without exploring all possible environment states? How can we verify not only safety but also robustness and fairness across the state space? No existing solution can satisfactorily answer all these questions. To address these challenges, we plan to develop grey-box FM and AT assessment techniques in this research. These techniques would consider a suitable abstraction of the RL agent’s state space to handle scalability issues. The fundamental research contribution in AT would be in developing “surprising” attacks for Single and Multi-Agent RL and quantifying the observed failures into a trustworthiness score. Further, to enable a systematic exploration of the RL agent’s state space, it is then important to develop techniques for determining the sample-size of tests to be performed on the RL agent with corresponding trustworthiness guarantees (size of the initial environment state space to be explored). Addressing this problem, the fundamental research contribution in FM would be to develop techniques for determining these sample-sizes with PAC-like (Probably Approximately Correct) guarantees for trustworthiness properties in Single and Multi-Agent RL. Thus, the complementarity of FM and AT methods will help to derive a reliable score for trustworthiness. While FM will provide probabilistic guarantees on trustworthiness based on a derived test sample-size, AT will use these samples to test and quantify the severity of trustworthiness violations if they occur.