Safety Assurance for Machine Learning in CPS
Research Motivation
Modern cyber-physical systems (CPS) such as autonomous vehicles and smart grids are expected to perform complex control functions under highly dynamic operating environments. Increasingly, to cope with the complexity and scale, these functions are being designed autonomously, often with the assistance of Machine Learning (ML) based techniques. A key challenge in the design of such safety-critical systems is that of achieving high assurance on system safety. One aspect of this challenge is that the ML models are complex and process extremely high-dimensional inputs such as images, thus rendering the resulting black-box controllers inaccessible to traditional safety assessment techniques. Another aspect of this challenge is that the correctness of such learning algorithms is critically dependent on the training data sets. In the case of CPS, these sets are often non-representative and missing rare, but important, safety-related hazard data.
Addressing the above two open problems, in this project we aim to develop a software architecture for achieving safety assurance in such systems. This architecture is inspired by the Simplex model of computation in which a complex and high-performance controller is coupled with a simple and conservative controller to ensure system safety. An efficient run-time decision module will then switch between the two controllers while ensuring safety at all times. To develop a verifiable safety controller, we aim to focus on scalable techniques with probabilistic correctness (probably approximately correct - PAC) guarantees for example using scenario optimization. For the run-time decision module, we aim to focus on statistically robust and computationally efficient techniques for out-of-distribution detection to quickly identify and deal with images that are outside the training space of learning enabled components.
Contributions
1. Out-of-Distribution Detection
 A practical technique for ML to avoid unsafe predictions is “Safe Fail”. If a model is not likely to produce a correct output, a reject option is selected, and the backup solution, a traditional non-ML approach or a human operator, for example, is applied, thereby causing the system to fail safely. For example, a support vector machine (SVM) like classifier with a reject option could be used for this purpose. The model will select a reject option if the classifier’s predictive output $\phi(x)$ does not exceed a certain threshold.
A practical technique for ML to avoid unsafe predictions is “Safe Fail”. If a model is not likely to produce a correct output, a reject option is selected, and the backup solution, a traditional non-ML approach or a human operator, for example, is applied, thereby causing the system to fail safely. For example, a support vector machine (SVM) like classifier with a reject option could be used for this purpose. The model will select a reject option if the classifier’s predictive output $\phi(x)$ does not exceed a certain threshold.
An implicit assumption made here is that the classifiers are most uncertain near the decision boundaries of different classes and the distance from the decision boundary is inversely related to the confidence that an input instance belongs to a particular class. This assumption is reasonable in some sense because the decision boundaries learnt by these models are usually located where many training samples with different labels overlap. However, if a feature space contains few or no training samples at all, then the decision boundaries of ML models may wholly be based on an inductive bias, thereby having much epistemic uncertainty.
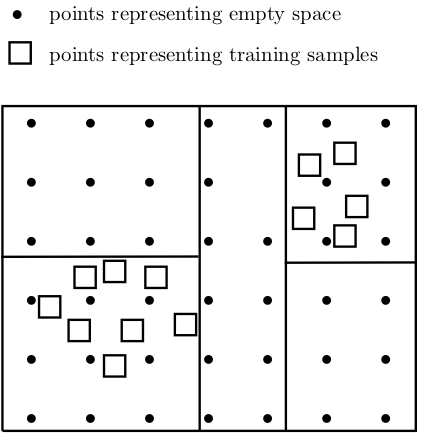
ML models learn from a subset of possible scenarios that could be encountered operationally. Thus, they can only be as good as the training examples they have learnt. Based on the observation that ML models work well in the “training space” with a cloud of training points, but they could not extrapolate beyond the training space, we propose a feature space partition tree (FSPT) to split the initial feature space into multiple partitions with different densities of training data. If an input instance is from a feature space partition with no or few training samples, then a reject option maybe selected.
2. Robust Out-of-distribution Detection and Localization
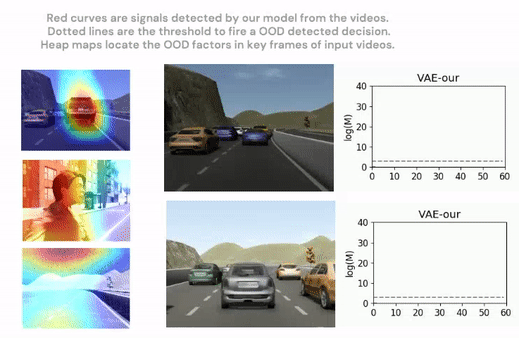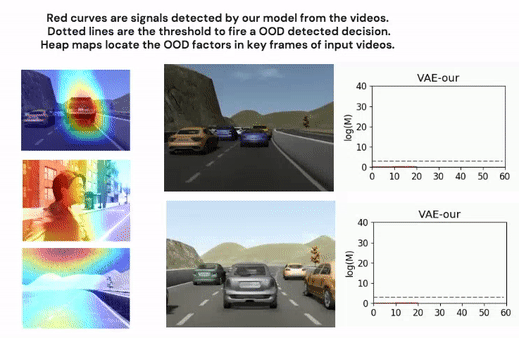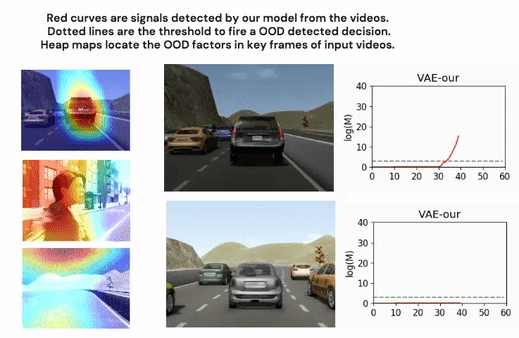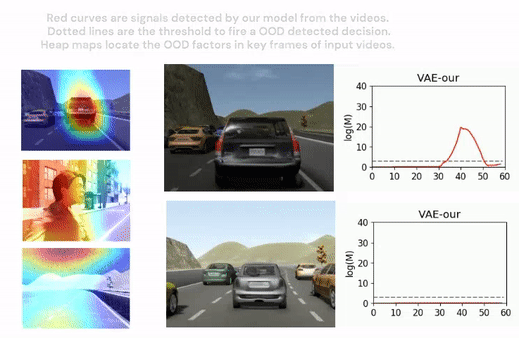 Highly complex deep learning modules are increasingly integrated into cyber-physical systems. Many of these systems have strict safety requirements. Deep learning is a modern approach to machine learning. Machine learning is inductive-based learning, so inductive bias is an inevitable risk. One necessary condition for such learning-based modules to function reliably is that data received at runtime is within the distribution of previously seen data during model training or fine-tuning.
Highly complex deep learning modules are increasingly integrated into cyber-physical systems. Many of these systems have strict safety requirements. Deep learning is a modern approach to machine learning. Machine learning is inductive-based learning, so inductive bias is an inevitable risk. One necessary condition for such learning-based modules to function reliably is that data received at runtime is within the distribution of previously seen data during model training or fine-tuning.
We propose an out-of-distribution detection methodology that hybrids classical optic flow operation with deep learning, variational autoencoder specifically. We demonstrate that the proposed method is statistically much more robust than related works on a driving simulation data set. We design an intuitive mechanism to facilitate the reasoning of detection results. Furthermore, we reduce the complexity of the detection system design.