Industry 4.0 has the potential to radically improve the productivity of manufacturing systems. The next generation of smart factories can perform more efficiently, collectively and resiliently. Existing resiliency techniques for the cyber-infrastructure of smart factories are inefficient due to two key limitations:
They do not consider cross-layer (link, network and application) interactions.
The techniques are centralised where all the decision making is mostly done at the highest-level.
Contributions
To enable a resilient cyber-infrastructure for Industry 4.0, we have presented a new contract-based methodology called CLAIR. Applications are described as a set of modular components that are distributed over a network. Contracts are used for describing the component’s interaction with other components (within and across layers). Finally, the contracts are monitored using runtime observers. We detect failures (contract violation) and react (change of contracts) to the disturbances, providing resiliency. Finally, using an industrial case study we validate the proposed architecture.
1. Proposed resilient cyber-infrastructure
We believe that the proposed 3-layered cyber infrastructure with cross-layer communication is the first approach that tightly couples resiliency with the self-awareness attribute of Industry 4.0. The physical layer comprises physical components such as sensors, actuators, controllers and communication hardware. The platform layer embodies computational and communicational platforms such as operating systems and network managers. The application layer accommodates software components which describe the behavior of an application. E.g., product sorting on an assembly line.
2. Overview of components & contracts
Interface: Defines the I/O data channels of a component. Data is consumed from the interface, processed by the component and data output is produced at the interface. Each component has only one interface. Behaviors: It is possible to describe multiple behaviors of the component. Each behavior is associated with a Quality-of-Service. At runtime, the resilience manager selects a behavior for the component. Contracts: A contract specifies assumptions on the behavior of the environment and guarantees about the behavior of the component. At runtime, the resilience manager can switch between behaviors to react to disturbances in the system. Resilience manager: Detects faults (using observers) and decides (resilience logic) how best to react (response strategy).
3. Observers for monitoring contracts
Static verification techniques are not generally adequate to validate whether a system meets the requirements (contracts satisfication). This may be because some of the requirements can only be validated with the data available at runtime (e.g. a sensor producing invalid data). As an alternative, system requirements can be monitored at runtime using observers. In our approach, observers are expressed using computational models such as finite state machines, timed automata or hybrid automata.
4. Hierarchical Resilience Framework
As an extension to the contract-based methodology, we present the hierarchical approach, which is to improve scalability and to allow for more meaningful communication between the resilience managers (RM) for fault recovery. Furthermore, we consider the use of contracts with parameters to provide efficient runtime updates to the hierarchy so that system degradation techniques (e.g., reducing the speed of a conveyor belt when a robot is unable to pick up from the belt) can be used for fault-recovery. The hierarchy also allows for the decomposition of the resilience management functions (contracts) which would aid in the scalability of the overall system.
Resilience management is the collaborative responsibility of a group of RMs. Each manager may have associated contracts that are used by observers to monitor the system for faults. A manager makes resilience decisions based on the information from its contracts as well as other managers. These managers follow a communication protocol that dictates to whom and what to talk about. Due to this protocol, a virtual management hierarchy of RMs and their associated contracts are created.
User provided end-to-end requirements, and component capabilities are used to generate the Assume-Guarantee (A-G) contracts. The component capabilities are first used to define leaf-level contracts. For example, contracts for a controller component could be derived from information about the host hardware and available alternate controller behaviors. Contracts from different components in a subsystem could then be composed to derive higher-level contracts in the hierarchy. Contract parameters can be derived based on tuneable performance knobs available in the system. For example, in manufacturing plants, the speed of conveyor belts can be used as a contract parameter to degrade the plant’s throughput. Functions based on these parameters could then be used in assumptions and guarantees of contracts. When contracts are composed, care must be taken to ensure that the resulting hierarchy satisfies desirable properties for contract composition and refinement. Additionally, it is also important to ensure that the root level contract satisfies (is a refinement of) user provided end-to-end requirements.
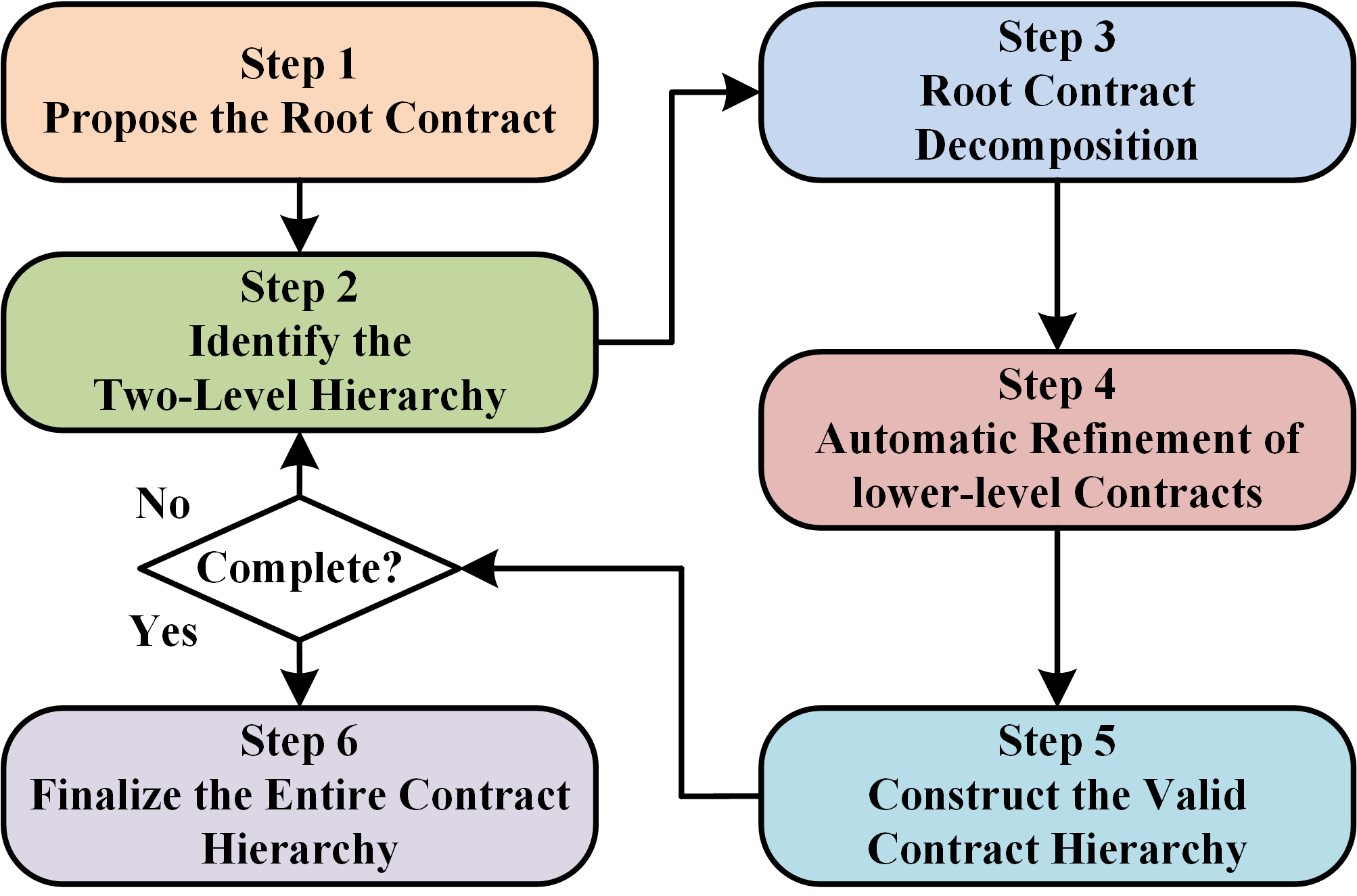
5. Automated Contract Generation and Refinement
It is challenging to compose the contract hierarchy shown above of a large-scale CPS due to its vast number of components. To address this issue, one can decompose the root contract (i.e., the original A-G contract) into multiple sub-contracts. Each sub-contract only monitors the Non-Functional Properties (NFPs) of a specific component in the system. However, such a simple and independent decomposition will make the CPS sensitive to random disturbances and false alarms. One false alarm in a component could impact the process of the entire system, increasing downtime and degrading system performance. For example, a jitter noise in a specific component may violate its sub-contract, shutting down the whole system when it could have resolved this jitter noise problem on its own. Further, such independent decomposition may not even be feasible in some cases, e.g., end-to-end latency requirements. Hence, a fully decentralized framework is also not always attractive.
To simplify the problem, we will view the entire hierarchy as multiple two-level contract-based hierarchies. Constructing a two-level contract-based hierarchy has two important steps: (1) decomposing the root contract into various sub-contracts; (2) refining the sub-contracts. The decomposition ensures that the framework can isolate the faulty components quickly. While the refinement guarantees that the root RM has some amount of flexibility to resolve random disturbances or false alarms, thus reducing the downtime of the system. We develop an algorithm to generate such hierarchical contracts automatically. As part of the automated solution, we propose a criterion to evaluate system performance based on the specific parameters of the contract and formulate an optimization problem to find the optimal settings.
If a CPS has multiple NFPs of interests, we can use the proposed mechanism to generate multiple independent contract hierarchies for monitoring different NFPs. Although our framework focuses on the generation of a two-level contract-based hierarchy, we can extend our work to multi-level hierarchies. As illustrated in the left figure, we can view a multi-level hierarchy as a combination of multiple two-level hierarchies under the same assumptions on NFPs. To generate a multi-level hierarchy, we can run the two steps proposed, iteratively.
6. Alternate Decomposition Method
As an alternative to the hierarchical methodology we employed above, we present a novel decentralized monitoring framework for non-functional properties (NFPs) using the notion of formula unwinding technique. The unwinding technique allows the NFP of the system to be decomposed into sub-formulas which can then be monitored independently by the processes of the system. Likewise, the original A-G contract represents the NFP of the system being monitored. This root contract (i.e.. a formula formalising a requirement over the system’s global behavior which is typically expressed as Boolean formula or Linear Temporal Logic formula). Our unwinding technique aims to transform the original formula into new formulae by breaking the dependency chain among the processes of the system such that all variables are explicitly observable. This would introduce new variables that were not observable in the original formula.
The CPS under consideration will have to fulfill the following assumptions:
The system is a synchronous system with a global clock.
We assume that each process p has a minimum response time (RT), and this represents the minimum time needed by process p to produce its output once the minimal set of required inputs to that process are available.
We assume the processes of the system make use of all their inputs when generating their outputs.
7. EdgeX-Resilience Package Implementation
EdgeX Foundry (EdgeX) is a vendor neutral, open sourced software platform that sits at the edge of the network, interacts with the physical devices (sensors, actuators) and other Internet-of-Things. It is a common framework for Industrial IoT Edge Computing. EdgeX provides a magnitude of functionalities. It provides a standard methodology to monitor physical world items, send instructions, collect data and move the data across the fog and up to the cloud where it can be stored, aggregated, analysed, which can then be actuated and acted upon. This is illustrated in the following figure, showing the various components that make up EdgeX Foundry.
The EdgeX-Resilience Package comes with three sub-packages:
EdgeX-Resilience Toolchain: Utility that is used for configuring and automating the contract generation process from the AutomationML (AML) file. The tool also generates the source file required to run as the RM on EdgeX (i.e., EdgeX-Resilience Application Service).
EdgeX OPC-UA Device Service: Enables OPC-UA communication between EdgeX and the Weintek IIOT Gateway. The gateway is responsible for communicating with the south-bound devices through Modbus TCP.
EdgeX-Resilience Application Service: The compiled executable which will be the resilience manager on EdgeX.
We encapsulate user provided end-to-end requirements, and component capabilities for a given system in a (AML) file. The AML file is fed into our software toolchain, which will decompose the root contract into its sub-contracts. Once the sub-contracts have been refined, as described in Section 5 above, a source file is generated for the application service. The application service represents our Resilience manager in our framework. The resilience manager contains the necessary functions to run the observers required for monitoring the subcontracts on EdgeX. In the source file, a template to perform recovery functions for each observer is also provided. The recovery functions needs to be manually specified by the application engineer.
For the resilience manager to communicate with the IMPACT line machines (i.e., Smart Transporter, Pick and Place, AOI and Laser Soldering), we’ve also provided a modified OPC-UA device service to communicate with the Weintek IIOT Gateway. This gateway in turn communicates with the IMPACT line machines through Modbus TCP.
Evaluation testbed & demonstration
Video Caption: Supplementary material for our paper; “Contract-based Hierarchical Resilience Management for Cyber-Physical Systems,” published in IEEE Computer. This is a assembly line setup for color-based sorting of tokens. In our implementation, we only use the first 2 bins and white tokens. Under normal operation, the white token would be ejected into the first bin. In case of a fault that requires changes to the conveyor belt speed, the second bin is used temporarily until fault-recovery is completed. When a fault occurs in the system, the following actions are expected.
(1) If the fault can be handled at the local resilience manager (color processor & bin selector), the fault information will not be propagated to the higher resilience manager (L1) and vice versa if the fault cannot be handled.
(2) If there is a missing token at LS2, ejector controller will report this failure to the L2 RM and eject the token to the second bin.
(3) At the root-level; i.e., L2 RM (Motor controller), it is possible to reduce the speed of the motor, allowing more time for the processing of sensor data.
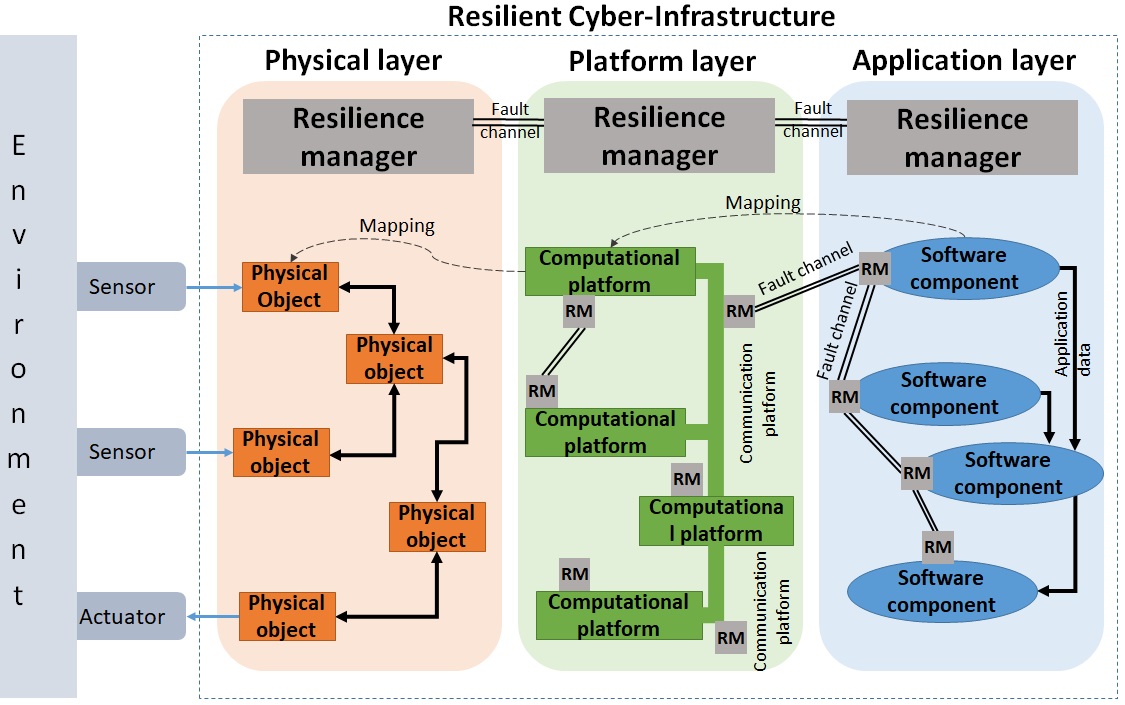 We believe that the proposed 3-layered cyber infrastructure with cross-layer communication is the first approach that tightly couples resiliency with the self-awareness attribute of Industry 4.0. The physical layer comprises physical components such as sensors, actuators, controllers and communication hardware. The platform layer embodies computational and communicational platforms such as operating systems and network managers. The application layer accommodates software components which describe the behavior of an application. E.g., product sorting on an assembly line.
We believe that the proposed 3-layered cyber infrastructure with cross-layer communication is the first approach that tightly couples resiliency with the self-awareness attribute of Industry 4.0. The physical layer comprises physical components such as sensors, actuators, controllers and communication hardware. The platform layer embodies computational and communicational platforms such as operating systems and network managers. The application layer accommodates software components which describe the behavior of an application. E.g., product sorting on an assembly line.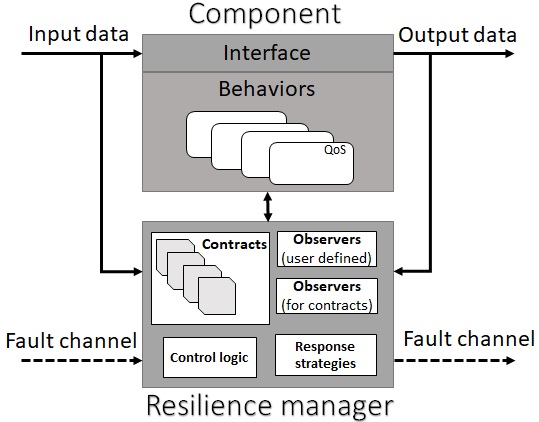 Interface: Defines the I/O data channels of a component. Data is consumed from the interface, processed by the component and data output is produced at the interface. Each component has only one interface.
Interface: Defines the I/O data channels of a component. Data is consumed from the interface, processed by the component and data output is produced at the interface. Each component has only one interface. Static verification techniques are not generally adequate to validate whether a system meets the requirements (contracts satisfication). This may be because some of the requirements can only be validated with the data available at runtime (e.g. a sensor producing invalid data). As an alternative, system requirements can be monitored at runtime using observers. In our approach, observers are expressed using computational models such as finite state machines, timed automata or hybrid automata.
Static verification techniques are not generally adequate to validate whether a system meets the requirements (contracts satisfication). This may be because some of the requirements can only be validated with the data available at runtime (e.g. a sensor producing invalid data). As an alternative, system requirements can be monitored at runtime using observers. In our approach, observers are expressed using computational models such as finite state machines, timed automata or hybrid automata.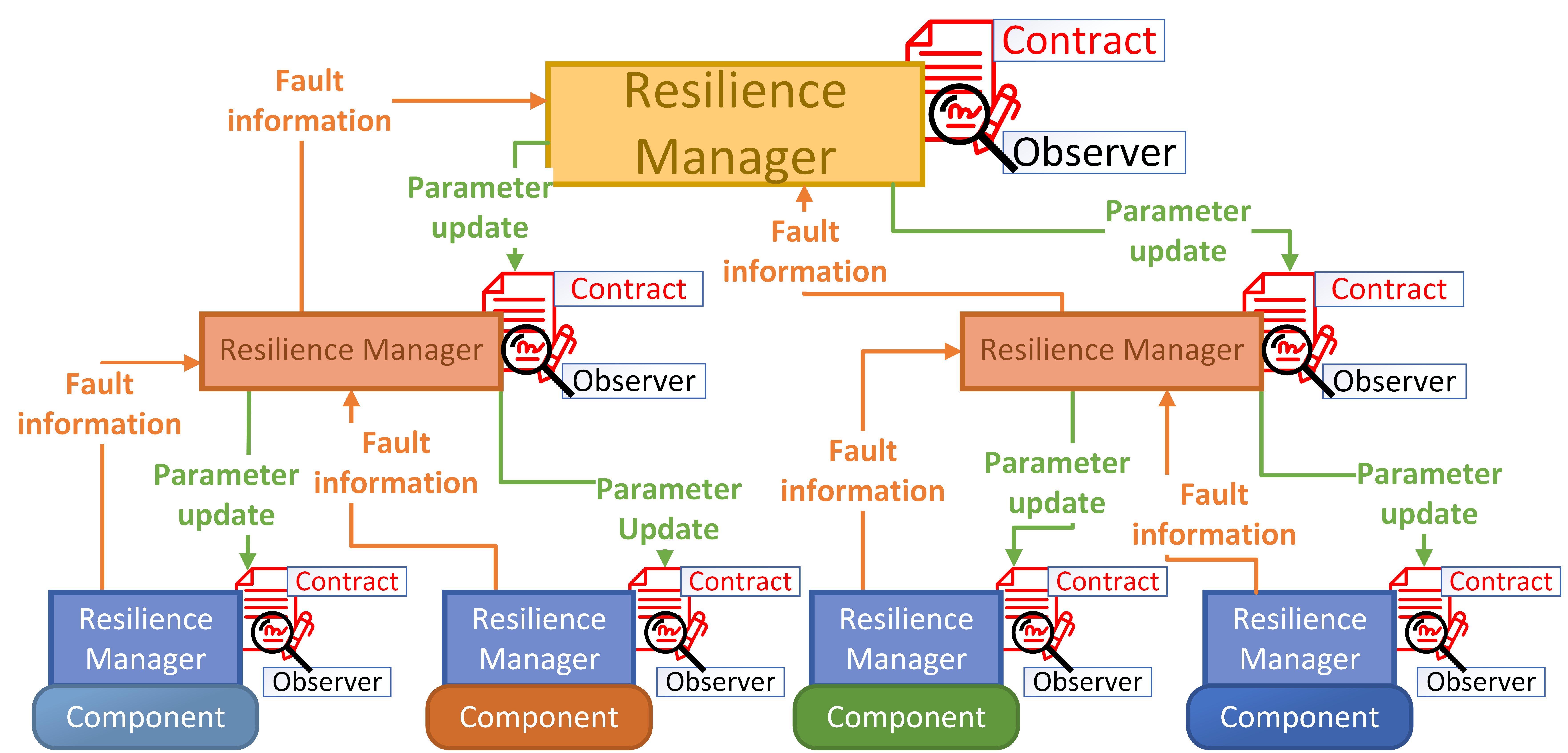 As an extension to the contract-based methodology, we present the hierarchical approach, which is to improve scalability and to allow for more meaningful communication between the resilience managers (RM) for fault recovery. Furthermore, we consider the use of contracts with parameters to provide efficient runtime updates to the hierarchy so that system degradation techniques (e.g., reducing the speed of a conveyor belt when a robot is unable to pick up from the belt) can be used for fault-recovery. The hierarchy also allows for the decomposition of the resilience management functions (contracts) which would aid in the scalability of the overall system.
As an extension to the contract-based methodology, we present the hierarchical approach, which is to improve scalability and to allow for more meaningful communication between the resilience managers (RM) for fault recovery. Furthermore, we consider the use of contracts with parameters to provide efficient runtime updates to the hierarchy so that system degradation techniques (e.g., reducing the speed of a conveyor belt when a robot is unable to pick up from the belt) can be used for fault-recovery. The hierarchy also allows for the decomposition of the resilience management functions (contracts) which would aid in the scalability of the overall system.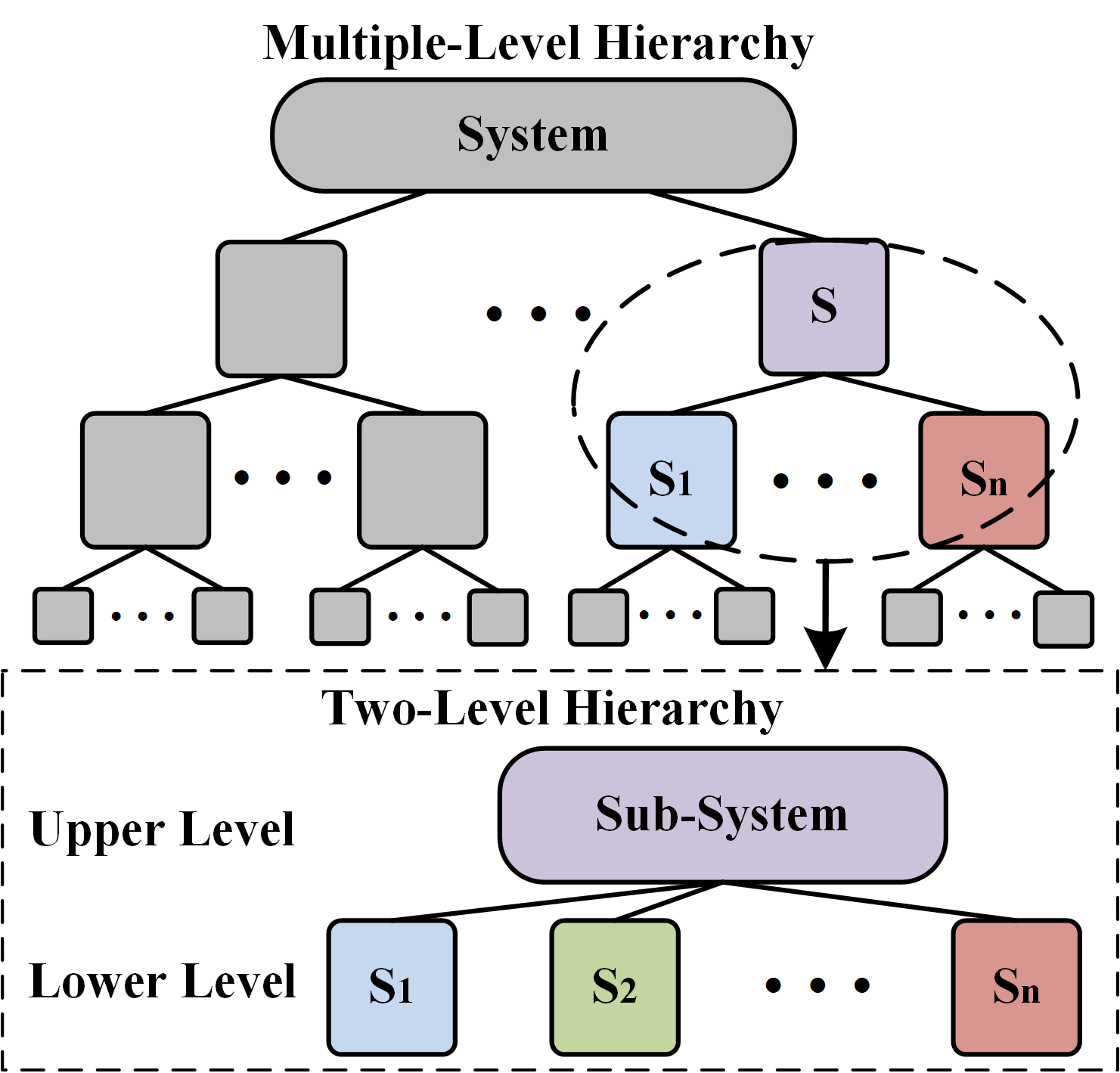
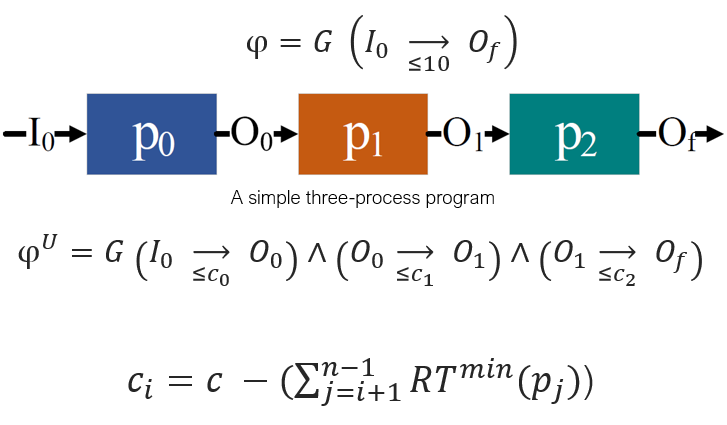 As an alternative to the hierarchical methodology we employed above, we present a novel decentralized monitoring framework for non-functional properties (NFPs) using the notion of formula unwinding technique. The unwinding technique allows the NFP of the system to be decomposed into sub-formulas which can then be monitored independently by the processes of the system. Likewise, the original A-G contract represents the NFP of the system being monitored. This root contract (i.e.. a formula formalising a requirement over the system’s global behavior which is typically expressed as Boolean formula or Linear Temporal Logic formula). Our unwinding technique aims to transform the original formula into new formulae by breaking the dependency chain among the processes of the system such that all variables are explicitly observable. This would introduce new variables that were not observable in the original formula.
As an alternative to the hierarchical methodology we employed above, we present a novel decentralized monitoring framework for non-functional properties (NFPs) using the notion of formula unwinding technique. The unwinding technique allows the NFP of the system to be decomposed into sub-formulas which can then be monitored independently by the processes of the system. Likewise, the original A-G contract represents the NFP of the system being monitored. This root contract (i.e.. a formula formalising a requirement over the system’s global behavior which is typically expressed as Boolean formula or Linear Temporal Logic formula). Our unwinding technique aims to transform the original formula into new formulae by breaking the dependency chain among the processes of the system such that all variables are explicitly observable. This would introduce new variables that were not observable in the original formula.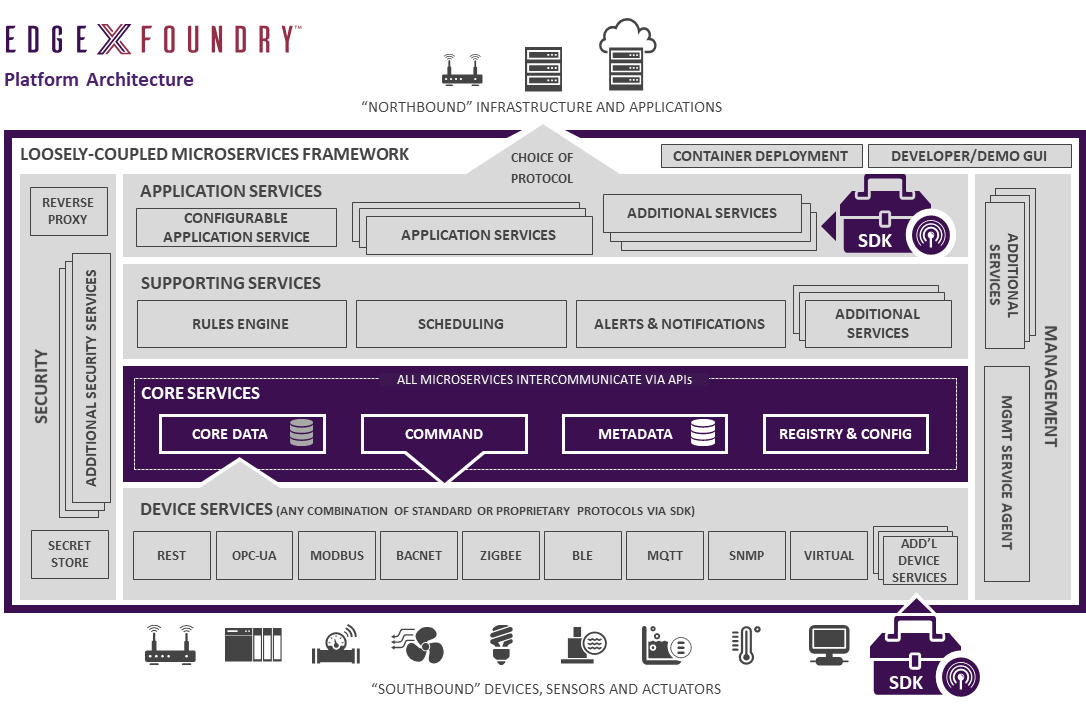 EdgeX Foundry (EdgeX) is a vendor neutral, open sourced software platform that sits at the edge of the network, interacts with the physical devices (sensors, actuators) and other Internet-of-Things. It is a common framework for Industrial IoT Edge Computing. EdgeX provides a magnitude of functionalities. It provides a standard methodology to monitor physical world items, send instructions, collect data and move the data across the fog and up to the cloud where it can be stored, aggregated, analysed, which can then be actuated and acted upon. This is illustrated in the following figure, showing the various components that make up EdgeX Foundry.
EdgeX Foundry (EdgeX) is a vendor neutral, open sourced software platform that sits at the edge of the network, interacts with the physical devices (sensors, actuators) and other Internet-of-Things. It is a common framework for Industrial IoT Edge Computing. EdgeX provides a magnitude of functionalities. It provides a standard methodology to monitor physical world items, send instructions, collect data and move the data across the fog and up to the cloud where it can be stored, aggregated, analysed, which can then be actuated and acted upon. This is illustrated in the following figure, showing the various components that make up EdgeX Foundry.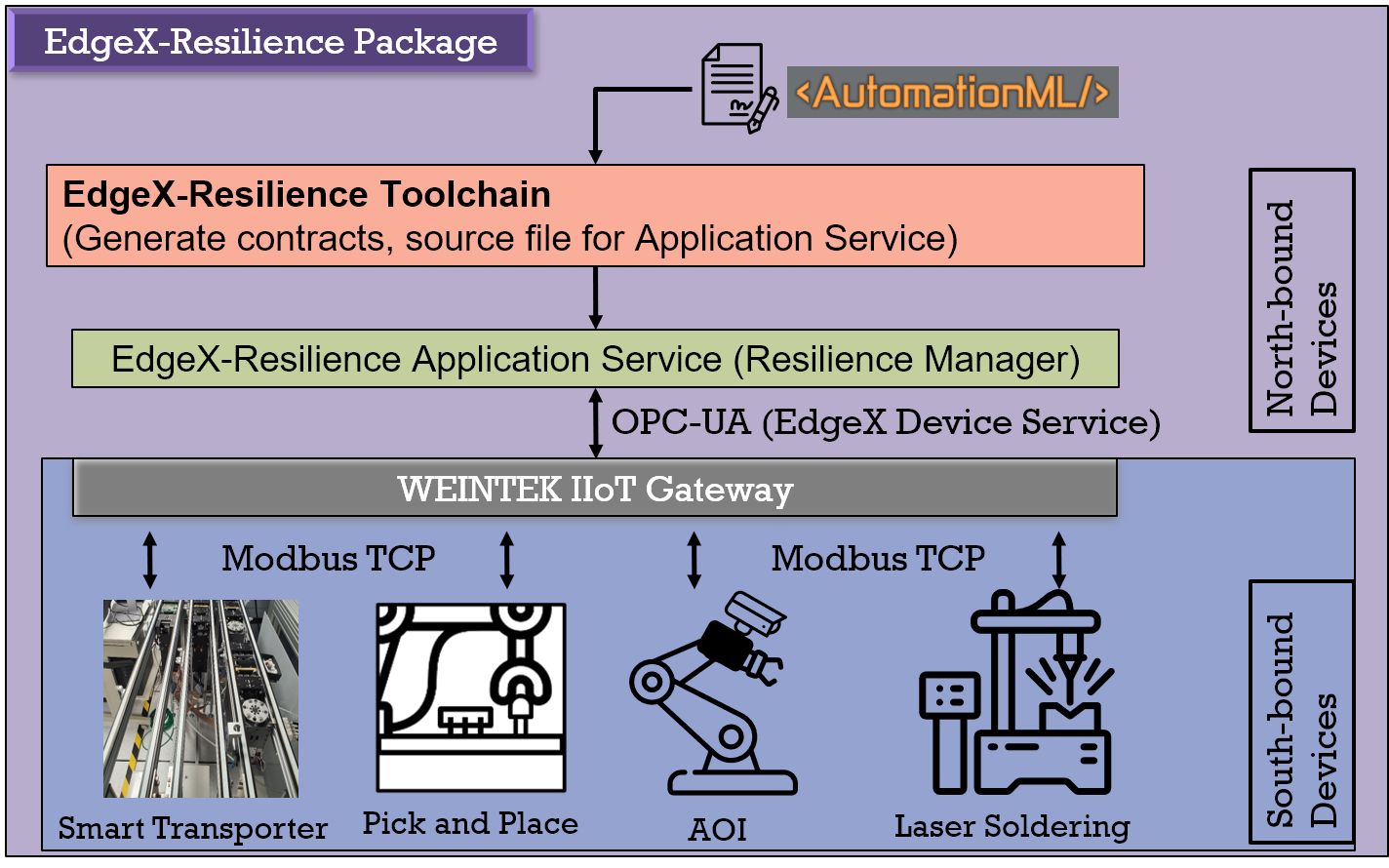 We encapsulate user provided end-to-end requirements, and component capabilities for a given system in a (AML) file. The AML file is fed into our software toolchain, which will decompose the root contract into its sub-contracts. Once the sub-contracts have been refined, as described in Section 5 above, a source file is generated for the application service. The application service represents our Resilience manager in our framework. The resilience manager contains the necessary functions to run the observers required for monitoring the subcontracts on EdgeX. In the source file, a template to perform recovery functions for each observer is also provided. The recovery functions needs to be manually specified by the application engineer.
We encapsulate user provided end-to-end requirements, and component capabilities for a given system in a (AML) file. The AML file is fed into our software toolchain, which will decompose the root contract into its sub-contracts. Once the sub-contracts have been refined, as described in Section 5 above, a source file is generated for the application service. The application service represents our Resilience manager in our framework. The resilience manager contains the necessary functions to run the observers required for monitoring the subcontracts on EdgeX. In the source file, a template to perform recovery functions for each observer is also provided. The recovery functions needs to be manually specified by the application engineer.